I’m by no means a prolific contributor to the Rust language (yet!), but I have submitted a few patches. One thing that I’m appreciating as I work on these is that it’s possible to figure out why something did (or did not) change since the development process of Rust is happening in the open. Using git, GitHub, the RFCs repo, and documentation, I have felt like I could figure anything out with a little digging. It’s so much more satisfying than languages that are closed source, haven’t documented the decisions made, or have the information more distributed across multiple forums, bug trackers, or mailing lists so that it’s harder to get the full picture.
In programming, I strongly believe that it’s not important to know all the answers off the top of your head, but it is VERY important to know how to figure out the answers you need, and you can make meaningful contributions if you have the latter but most people don’t even try because they feel like they’re supposed to have the former.
I’ve decided to write down my thought processes and the techniques I’ve used while working on a change in order to give some ideas to people who might be feeling overwhelmed or stuck, and to demonstrate that, even though I know very little about how the Rust compiler works, I can help. I’d love to hear about more places/ways I could be looking or about interesting information you’ve found out using these sorts of techniques!
So! Lately, I’ve been working on the grammar documentation, trying to make sure the patterns that explain what is valid in the language are up to date with the code that parses the language since the language is settling down with the 1.0 release impending. The grammar documentation is useful to people writing syntax highlighters, among other things. In this post, I am assuming a general familiarity with EBNF and the variant this Rust document is choosing to use, but I promise they’re essentially a set of rules of substitutions that define what is valid in a language, nothing more. You can totally learn the concepts if you haven’t heard of EBNF before, especially if you’re familiar with regular expressions.
Today, I was working on the Items section and got to the Modules > View items > Use declarations subsection, which at this point in time reads:
use_decl : "pub" ? "use" [ path "as" ident
| path_glob ] ;
path_glob : ident [ "::" [ path_glob
| '*' ] ] ?
| '{' path_item [ ',' path_item ] * '}' ;
path_item : ident | "mod" ;
After reading this closely, I noticed what seemed to be like a few issues:
path isn’t defined anywhere (not even in another section in this document)-
`use foo{bar}` (without the `::` between `foo` and `{`) would be valid and I don't think it is
I was totally wrong that the definition allowed this, see the “IN WHICH I REALIZE I’M TOTALLY WRONG” section. I’m leaving this in rather than correcting it because I think it’s important to demonstrate how research can change your understanding of something.
use foo::{mod} (using the keyword mod) would be valid and I don’t think it is; I don’t remember seeing this in code I’ve read and git grep -h use | grep mod in the rust repo doesn’t turn up any use declarations that have mod
The second problem seem to be because of ambiguous grouping. These are valid if the grouping is:
THIS IS TOTALLY WRONG SEE BELOW
ident [ "::" [ path_glob | '*' ] ] ?
|
'{' path_item [ ',' path_item ] * '}'
But not if the grouping is:
ident
[ "::" [ path_glob | '*' ] ] ?
|
'{' path_item [ ',' path_item ] * '}'
(whitespace altered to make the groups a bit clearer)
So now I want to figure out if I’m correct that these are issues (SPOILER I’M NOT SEE BELOW), and then figure out what these definitions should be.
Are these issues?
In trying to figure out if things I find in code are, in fact, problems, I’ve found two questions to be useful to ask:
- How did this get to be the way it is today? (history)
- Does it match the current state of the rest of the code? (present)
Let’s start with the history! Git is really good at keeping track of the history of changes. There are a few tools git provides that could be useful in this case:
- I could use
git log src/doc/grammar.md to read the whole history of this file
- I could use
git blame src/doc/grammar.md to see which commit last changed each line in the file
- I could use the git “pickaxe” search to look for commits that added or removed occurrences of particular text, such as
git log -Gpath_glob
Taking a quick look at the log of the file, and especially with the stats that git log --stat src/doc/grammar.md shows, it looks like a lot of the grammar was added to this file in the first commit to it, ffc5f1c. A GitHub trick I like to use is searching for the commit hash to find the pull request this commit was part of:
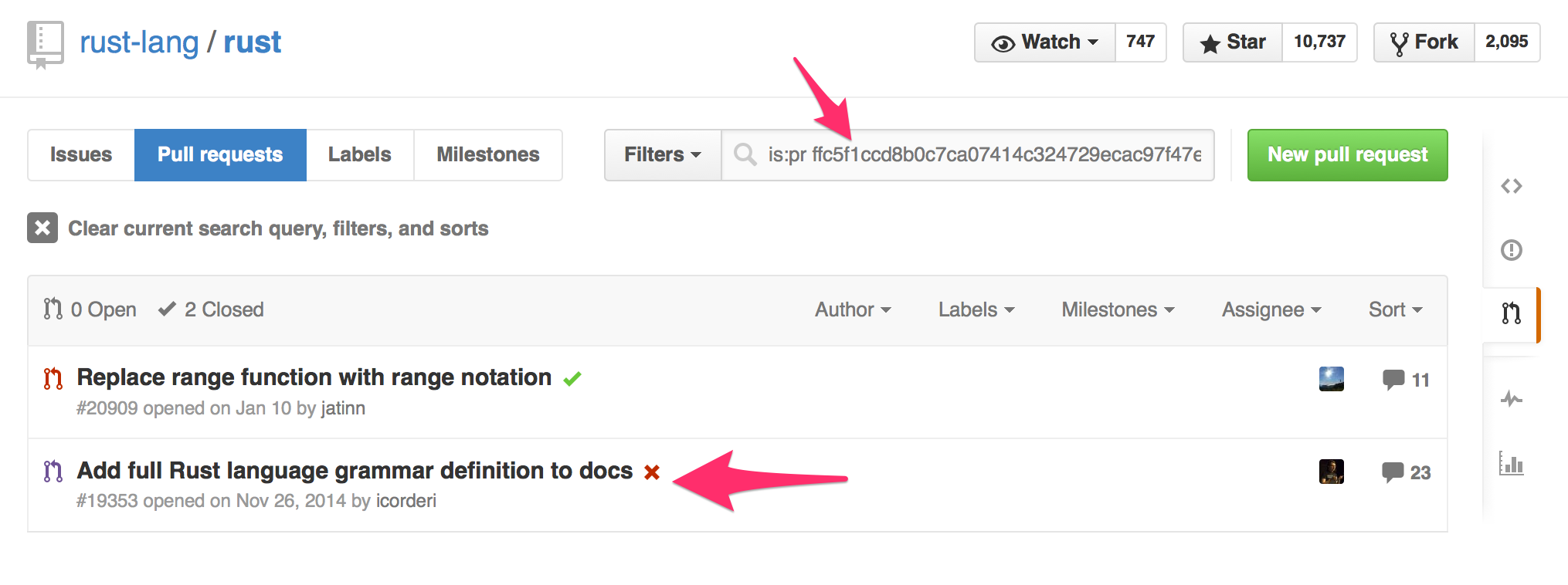
This is awesome, because in the PR description it says “The current state of the PR contains all the grammars that were available in reference.md and nothing else.” So this content that looks brand new actually has more history as part of reference.md!
So if I do git log src/doc/reference.md, I get… a lot of commits. git log --format=oneline src/doc/reference.md | wc -l => 356 commits as of today, to be exact. I don’t know about you, but I’m not about to look through all of those individually. I did look at the first commit, though, which shows that THIS file actually used to be src/doc/rust.md, and that the section I’m interested in had the same issues at that point.
If I look at the first commit to src/doc/rust.md, the section I’m interested in is different at this point!
use_decl : "pub" ? "use" ident [ '=' path
| "::" path_glob ] ;
path_glob : ident [ "::" path_glob ] ?
| '*'
| '{' ident [ ',' ident ] * '}'
Taking a search through the whole document at that version, it seems like path still isn’t defined anywhere, so this version still has issue #1. But use foo{bar} would NOT be valid here because use_decl has a requirement of "::" before the path_glob. Also, path_item with "mod" does not appear. So I’ve got a good range to know when some of the changes I’m interested in have been made!
git log --format=oneline src/doc/rust.md | wc -l shows 179 changes, more manageable but I still don’t want to look through all of them manually. At this point, I’m going to pull out git’s pickaxe search. Usually, you’ll see the concept of a pickaxe search being done using git log -Ssomestring, which will show commits where that string was added or removed from a file, but I more often like git log -Gsomestring, which also shows when lines in a file containing that string appeared in a diff, that is, those lines were changed.
If I do git log -Gpath_glob src/doc/rust.md, I get the two commits that moved this content around AND a commit between them that says “Correct EBNF grammar in the manual”, “The grammar for use declarations was outdated.” This looks relevant to my interests! If I do a GitHub search for the pull requests, I can see some discussion from a year ago about WHY these changes are being made. Most interesting to me are the examples that show with these changes, use {many, idents}; would be correctly valid and use *; would be correctly invalid.
IN WHICH I REALIZE I’M TOTALLY WRONG
Up until this point, I thought the current grammar allowed use foo{bar};. Something about seeing the example of the valid use {many, idents}; that I hadn’t thought of as existing, much less being valid, made me look at the current grammar rules again and realize that use foo{bar}; is actually NOT allowed. If I was going to aim for making use foo{bar}, I’d have follow the path of these substitutions starting from use_decl:
use_decl
"pub" ? "use" [ path "as" ident | path_glob ] // initial expansion
"use" [ path "as" ident | path_glob ] // choose to have 0 "pub"s
"use" path_glob // pick the 2nd arm of the use_decl rule since I don't want "as"
"use" ident [ "::" [ path_glob | '*' ] ] ? // pick the 1st arm of the path_glob rule since I want `foo`
// Important part
"use" ident "::" [ path_glob | '*' ] // choose to have the ? be 1 time, not 0, BAM I have to have `::` in there!!!!
// Continuing with the substitutions to show how it plays out
"use" ident "::" path_glob // pick the 1st arm of the choice I have remaining
"use" ident "::" '{' path_item [ ',' path_item ] * '}' // pick the 2nd arm of the path_glob rule
"use" ident "::" '{' path_item '}' // choose to repeat 0 times
"use" ident "::" '{' ident '}' // pick the 1st arm of the path_item rule
"use" "foo" "::" '{' "bar" '}' // substitute in my idents
I think I was getting confused about where the recursion was happening. Now that I see it this way, it’s hard to see exactly why my brain thought it was a different way (even just 5 minutes ago)! Anyway, I’m not going to spend even a minute feeling bad for my mistake, because it looks like reading and comprehending a grammar definition is hard even for a really smart person :)
SO! I can cross #2 off my list!
Moving right along
Let’s take a look at #3 then. I’m still not so sure about the validity of the mod keyword in this context. But the commit I just found using the pickaxe search looking for #2 wasn’t the source of the introduction of that. So I’m going to try git log -Gpath_item src/doc/rust.md instead. This leads me to one of the commits that moved this content around and a new commit whose message is “Add use a::b::{c, mod}; to the manual”. Cool! There isn’t really much discussion on the pull request this commit came in with, but looking at the full diff, I see it changed some of the surrounding documentation that now lives in reference.md, namely “Simultaneously binding a list of paths differing only in their final element and their immediate parent module, using the mod keyword, such as use a::b::{mod, c, d};” So at the point in time of this commit, this was indeed valid syntax! But what about now? At this point, I’m going to switch from looking at history to looking at the present state. This bullet point does exist in the current reference.md, but it now says “Simultaneously binding a list of paths differing only in their final element and their immediate parent module, using the self keyword, such as use a::b::{self, c, d};” Neat! So at some point, the way to do this was changed from using the mod keyword to using the self keyword and the grammar didn’t keep up with the change! To be absolutely sure, I’m going to look for that change by using git log -G "and their immediate parent module, using the \`self\` keyword, such as" to see when that line appeared in a diff. That gets me 195fd9a, which says “This should have been done together with 56dcbd1”. But wait. If I look at the diff of 195fd9a, it looks like the change to path_item’s definition that I’m trying to figure out if I need to make has already been made!!! What?!
At this point, I will admit that I have some knowledge just from having been paying attention to the changes happening in this area for a bit, but I think this is discoverable using the techniques of following changes around that I’ve been demonstrating. When this separate grammar.md file was introduced, it was created from COPIED content from reference.md, but that content wasn’t REMOVED, and that content evolved separately. Just recently, though, the grammar sections in reference.md were MOVED over to grammar.md and grammar.md is now linked to from reference.md. I’ve just discovered that at least one section that already existed in grammar.md wasn’t overwritten but should have been since the reference had the more recent content, and now I’m really intrigued because there’s a broader situation to look into and verify that there are or are not other sections that need updates, so I’ve potentially discovered a need for a fix that’s more than one line! Not that there’s anything WRONG with a one line change, mind you, just that there is an overhead to each commit/pull request for both the submitter and maintainers, and it’s always good when you can find CLASSES of problems and fix them rather than individual INSTANCES of problems.
I’m going to spare you the boring details of checking each section removed from the reference against what existed in the grammar, but my efforts resulted in this commit; I found 5 spots.
And back for one more
Now, you’ll notice I’ve mostly been avoiding problem #1. That’s because it’s the hardest one– if path has never existed in any form, what is it supposed to be?
Before considering that question, I’m going to check the history a little bit more to be sure this wasn’t a missed rename, since I noted that when doc/rust.md was moved to src/doc/rust.md, the document at that version had this problem already. I started by trying git log -Gpath -- doc/rust.md (I’m not sure why git needs the -- in this one but not the previous commands, but oh well. Maybe because one slash could be a remote/branch but two slashes is clearly a filename?), but that yielded a lot of false positives of prose containing “path”. I also tried git log -G" path[^s]" -- doc/rust.md, that got me fewer, but I decided to just start looking at commit messages and git showing ones that looked potentially related, then using / path in less when looking at the diff.
Then I realized I was being silly– if I’m looking for a potentially-existing-at-some-point definition of path, it would be at the beginning of a line and be followed by a space then a colon (assuming it followed the same conventions as the rest of the file). So that would be git log -G"^path :" -- doc/rust.md. And… nothing. I also tried leaving the filename off; that took a long time to also return nothing. Next I tried git log -Guse_decl -- doc/rust.md, found out a bit about how Rust syntax used to be, but still no clear path definition – everything just referenced the Paths section that only defined expr_path and type_path. I eventually got back to the commit introducing doc/rust.md, which says “Begin shift over to using pandoc, markdown and llnextgen for reference manual”, but doesn’t say shift FROM what. Considering there are no deletions, only additions, of the content I’m interested in, I’m assuming it lived somewhere outside of this repository. Dead end!
Since this post is getting rather long, you’re going to have to tune in next time to see if I just end up adding path : expr_path | type_path ; or if it’s more complicated than that!! Best of luck on your own journeys exploring code :)

![Results of which do you like best, winners are arr.sort.chunk(&:itself).map {|v, vs| [v, vs.count]}.to_h with 10 votes (24.4%) then arr.uniq.map { |x| [x, arr.count(x)] }.to_h with 9 votes (22%)](/assets/img/like.png)
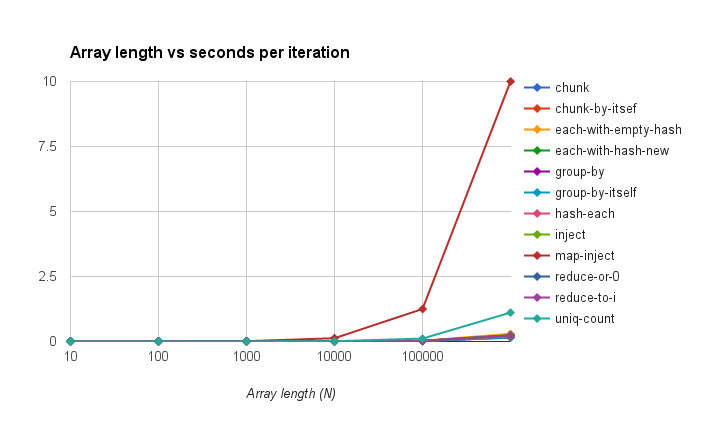
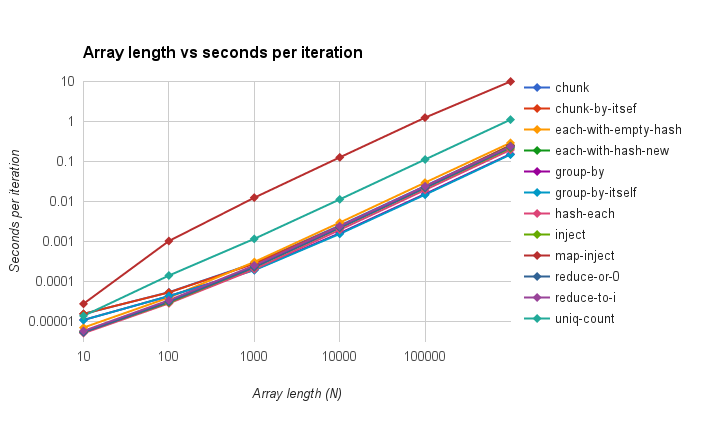
![Results of which do you think is fastest, winners are h = Hash.new(0); arr.each { |l| h[l] += 1 }; h and arr.sort.chunk(&:itself).map {|v, vs| [v, vs.count]}.to_h, both with 11 votes (26.8%)](/assets/img/fastest.png)

{kind=link}