
Ruby Occurrence Counting
Last night, I was coding, as one does, and I wanted something that I thought FOR SURE there was a method in Ruby’s Enumerable module for already, because Enumerable is awesome and The Best Module Ever. But alas, there is not. My problem was:
Given an array like:
arr = ["a", "b", "a", "c", "c"]
You want a count of the occurrences of each item in the
array, as a hash with the unique items in the array as
the keys, and the number of occurrences as the values.
The desired result in this example is:
{"a" => 2, "b" => 1, "c" => 2}
I read through all of enumerable, then tried my hand at a solution, and it just wasn’t pretty or satisfying. This is unusual for Ruby! So what did I do? I asked my coworkers and I asked twitter.
Between all of us, we came up with 12 significantly different solutions:
arr.uniq.map { |x| [x, arr.count(x)] }.to_h
h = Hash.new(0); arr.each { |l| h[l] += 1 }; h
arr.reduce({}) { |m, a| m[a] = m[a].to_i + 1; m }
arr.inject(Hash.new(0)) { |h, i| h[i] += 1; h }
arr.sort.chunk { |ex| ex }.map { |k, v| [k, v.length] }.to_h
arr.reduce({}) { |ret, val| ret[val] = (ret[val] || 0) + 1; ret }
arr.each_with_object(Hash.new(0)) { |word, counts| counts[word] += 1 }
arr.each_with_object({}) { |item, memo| memo[item] ||= 0; memo[item] += 1 }
arr.map { |x| { x => 1 } }.inject { |a, b| a.merge(b) { |k, x, y| x + y } }
arr.group_by { |x| x }.map { |element, matches| [ element, matches.length ] }.to_h
Hash[arr.group_by(&:itself).map {|k,v| [k, v.size] }] # Must also upgrade to Ruby 2.2 or Rails 4
arr.sort.chunk(&:itself).map {|v, vs| [v, vs.count]}.to_h # Must also upgrade to Ruby 2.2 or Rails 4
I love the variety! I love that there’s not a clear right answer! I love that the solution is evolving over newer versions of Ruby (that I’m not on yet)!
And as if this wasn’t Tom Sawyerish enough, I decided we then needed to have a vote. As of this writing, with the polls open about 24 hours, I’ve had 41 responses to these 3 questions:
![Results of which do you like best, winners are arr.sort.chunk(&:itself).map {|v, vs| [v, vs.count]}.to_h with 10 votes (24.4%) then arr.uniq.map { |x| [x, arr.count(x)] }.to_h with 9 votes (22%)](/assets/img/like.png)
![Results of which do you think is fastest, winners are h = Hash.new(0); arr.each { |l| h[l] += 1 }; h and arr.sort.chunk(&:itself).map {|v, vs| [v, vs.count]}.to_h, both with 11 votes (26.8%)](/assets/img/fastest.png)

So then, of course, I had to benchmark the results. And I don’t benchmark things very often, so I don’t know how to do it off the top of my head, but luckily I had Schneems’ Rails pull request open in another tab where someone benchmarked parts of the code using evanphx’s benchmark-ips gem. And a number of things appealed to me in the gem’s readme, namely “No more guessing at random iteration counts!” If there’s anything I know, it’s that I don’t know how to pick iteration counts. The code I used is on GitHub, and I’m sure I messed something up– please send me pull requests if there are improvements to be made!
So I put all the solutions into a Benchmark.ips block, using powers of 10 for the length of the array we’d be counting (this is the n in the Big-O analysis). I used a sampling of lowercase letters in the English alphabet for the values. Benchmarking arrays that are all the same value or all different values instead of a random distribution of values is left as an exercise to the reader.
TL;DR You’re Not Gonna Like The Results
The absolute winner is:
Hash[arr.group_by(&:itself).map {|k,v| [k, v.size] }]
There are two things that I don’t think yinz are going to like about these results:
- In my opinion, the differences between the fastest 10 solutions are insignificant. So you’d be fine going with any of those; it’s purely your preference and benchmarking does not give us one unequivocally “best” answer.
- The shortest example that 22% of people liked best is significantly slower. Yup, that one looked most elegant to me too! But 7.5x slower isn’t anything to sneeze at.
Here’s the text output of the script I ran. It cuts off because I let it run overnight and it still wasn’t done in the morning, but we did get full runs up to n = 1,000,000.
The last section in each run shows the comparison of the candidates to each other; here’s that section for 1,000,000 items:
Comparison:
group-by-itself: 6.7 i/s
group-by: 6.5 i/s - 1.03x slower
hash-each: 5.1 i/s - 1.29x slower
inject: 4.6 i/s - 1.44x slower
reduce-or-0: 4.4 i/s - 1.52x slower
reduce-to-i: 4.2 i/s - 1.60x slower
each-with-hash-new: 4.1 i/s - 1.63x slower
chunk: 4.0 i/s - 1.67x slower
chunk-by-itself: 3.9 i/s - 1.71x slower
each-with-empty-hash: 3.4 i/s - 1.96x slower
uniq-count: 0.9 i/s - 7.49x slower
map-inject: 0.1 i/s - 90.93x slower
You’ll have to look at my code to see which names correspond to each solution.
In order to get the nice, Big-O like graphs that I remember learning all about in college, I took the iterations per second from each N’s comparison section of the results, took the inverse so that I had seconds per iteration, and compiled them in a spreadsheet then made a graph of the data on a logarithmic scale:
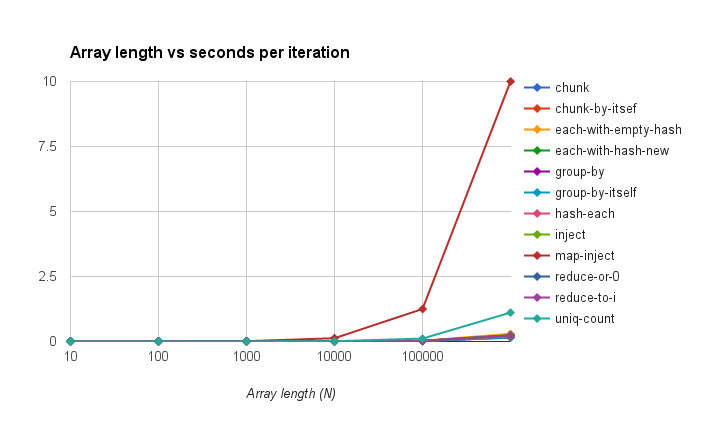
UPDATE 2015-08-08: Gankro kindly mentioned that I didn’t put the y-axis in logarithmic scale originally, here’s the fixed version. This lets you see more differences between the 10 similarly-performing solutions:
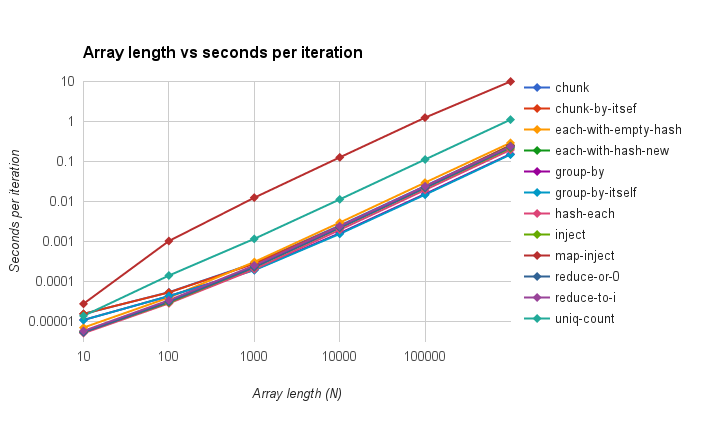
So there you go! Go forth and benchmark your own code!